Background
I started a project in December 2024 to build DeepSeek V2 from scratch. This is inspired by Andrej Karpathy’s Let’s build GPT: from scratch, in code, spelled out. It is really a great video and I highly recommend you to watch it. Andrej built GPT2 from scratch and showed how to improve the model performance step by step. In my project, I want to do the similar thing and go beyond just the pretraining to include Supervised Fine-tuning(SFT) and Reinforcement Learning with Human Feedback(RLHF).
This blog is a working in progress documentation and record what I learn from training DeepSeek V2.
If you are interested in the project, you can find the code at https://github.com/liyuan24/deepseek_from_scratch.
Batch Size Matters
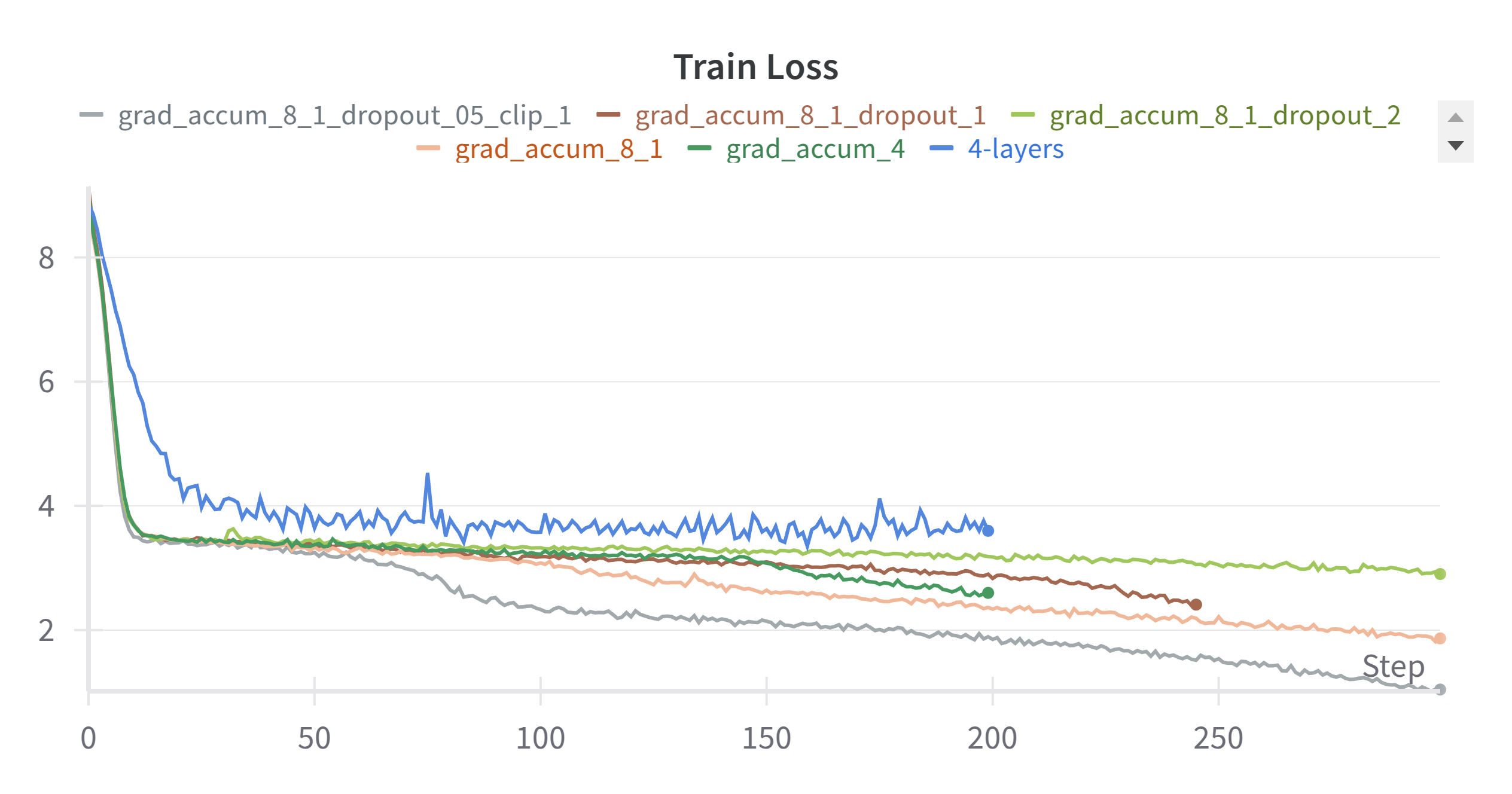
After finishing the model code, I started to train it. I have a GTX 3090 24G GPU and I can only train the model with batch size of 8. At first the training loss can only go down to 3.5. I adjusted the learning rate, but it didn’t help. Then I tried the gradient accumulation by setting the gradient accumulation steps to 4 which means the effective batch size is 32. The training loss can go down to 2.6.
The below figure is the training loss and validation loss with different batch sizes.
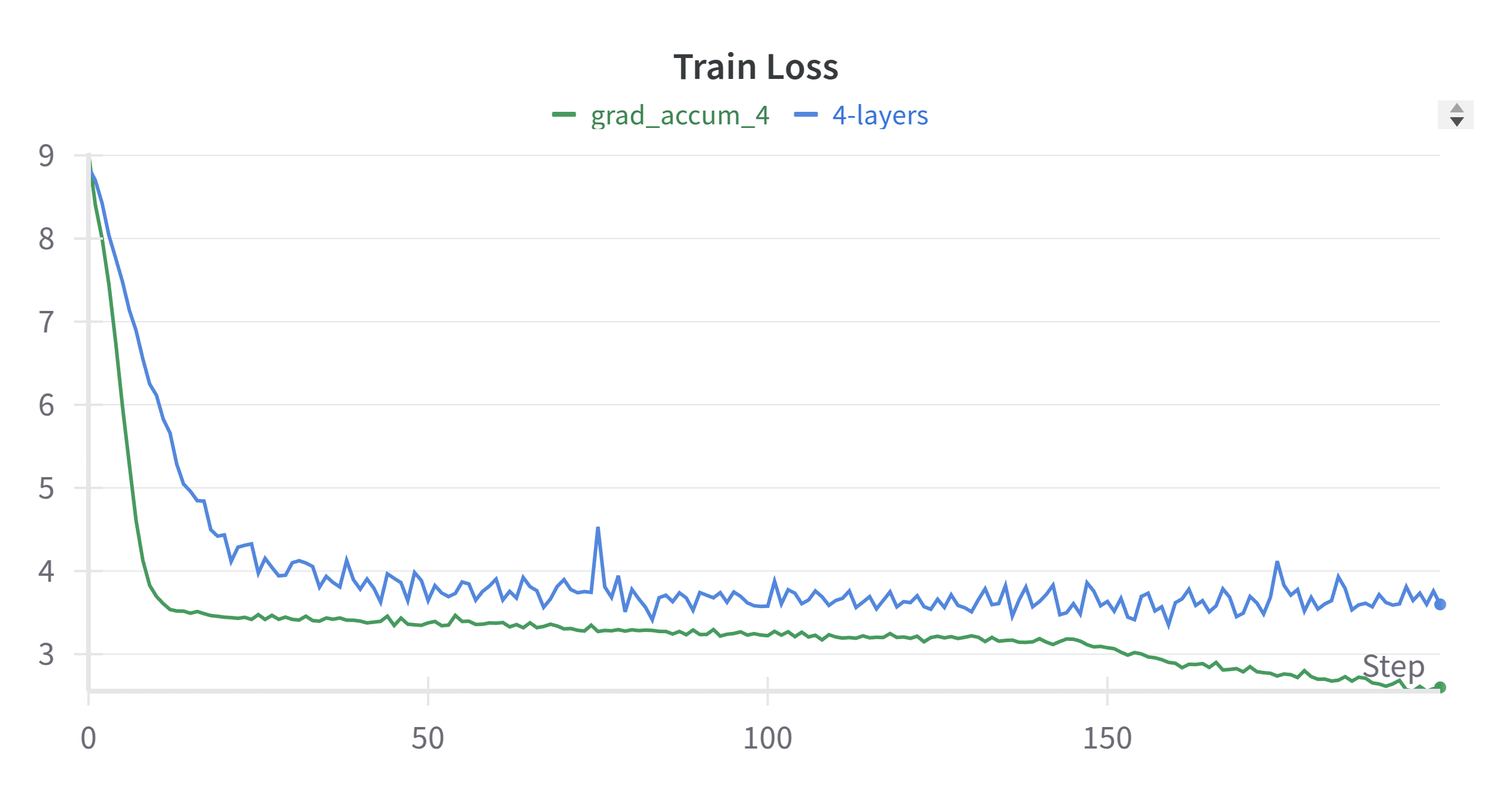
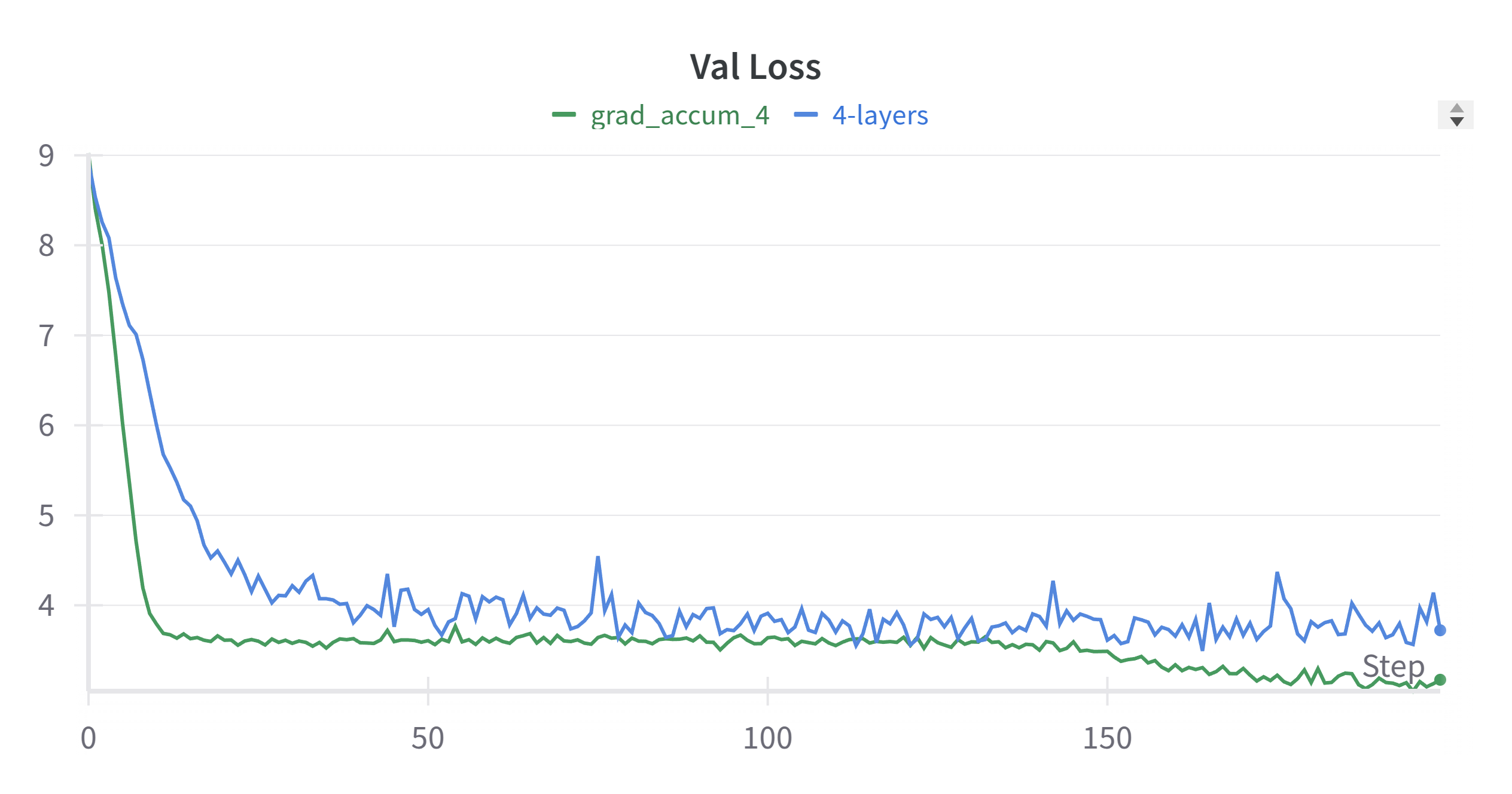
The training loss can be further improved by increasing the gradient accumulation steps rom 4 to 8. The below figure is the training loss and validation loss with gradient accumulation steps of 8.
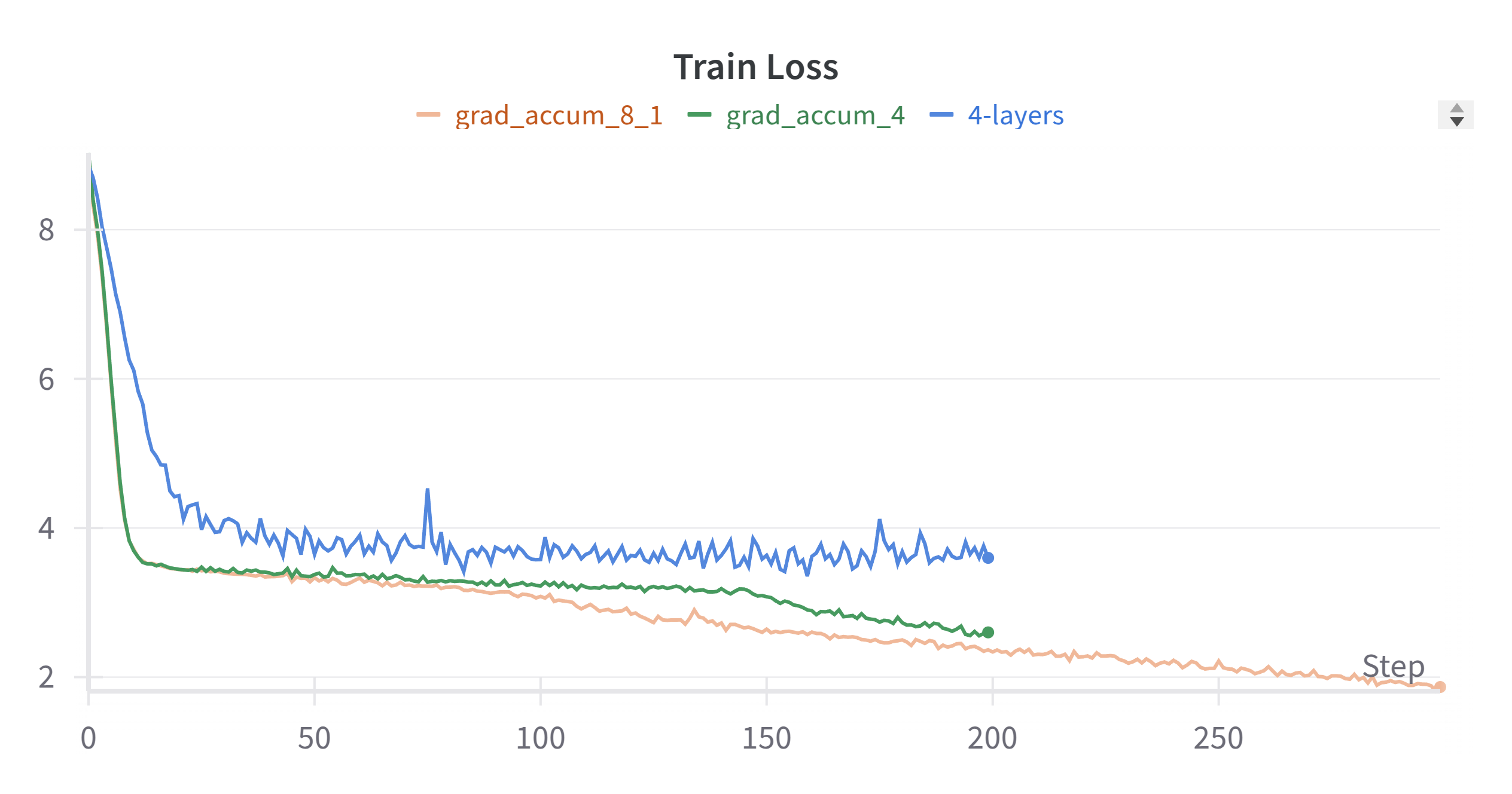
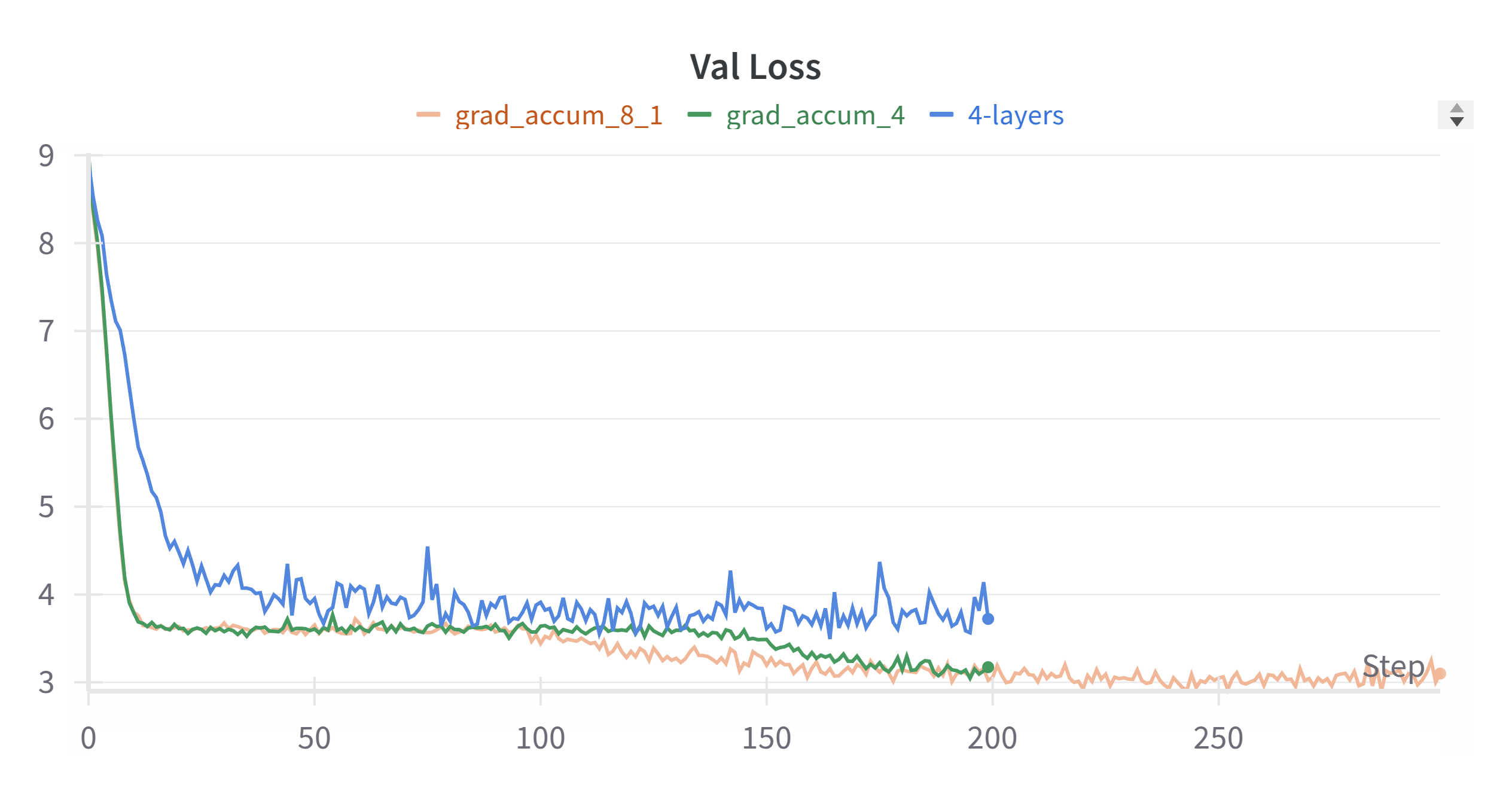
The gradient accumulation can be used when you want to increase the batch size, but the GPU memory is not enough. It will accumulate the gradient across multiple steps and then update the model parameters. The code is very simple
for _ in range(args.gradient_accumulation_steps):
with ctx:
_, loss, _ = model(x, y)
x, y = get_batch(
data_dir,
"train",
args.batch_size,
args.max_position_embeddings,
args.device,
)
loss = loss / args.gradient_accumulation_steps
loss.backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
Gradient Norm Clip Can Speed Up Training
After using the gradient norm clip at 1.0, the training speed is significantly improved.
if args.grad_clip > 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)